

Introduction
AI workloads are no longer confined to a single data center. They’re often distributed across multiple clouds and edge locations. Consequently, the need for flawless network synchronization has surged. Yet, one rarely monitored network performance metric—unlike packet drops or utilization—remains the primary obstacle: packet delay variation, or jitter.
Microsecond delays can rapidly escalate into massive cost overruns. GPUs must wait at synchronization barriers for the slowest node, resulting in nonlinear spikes in idle time and dramatic increases in workload duration. Moreover, cloud GPU billing is based on elapsed time—the duration a GPU-attached virtual machine (VM) or instance remains provisioned and running, regardless of actual utilization. This means even minor jitter can translate into thousands of dollars per day in added charges from the hyperscalers many organizations rely on for AI infrastructure.
Recent research from Juniper Networks dramatically illustrates this.1
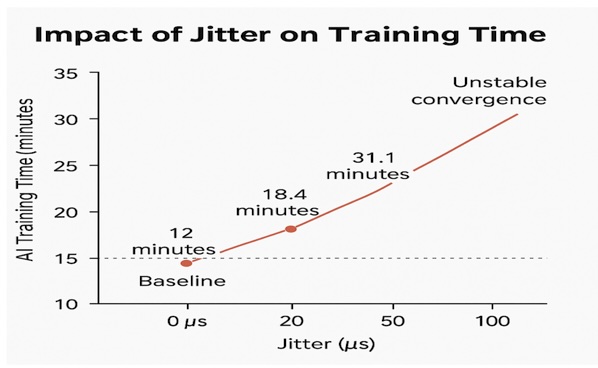
In highly controlled data center tests using NCCL workloads on a 32-NVIDIA A100 GPU cluster, Juniper injected 20-100 microseconds of jitter and observed the following results (as shown in the graph):
- Baseline (no injected jitter): 12 minutes per iteration
- With 20 µs of jitter: 18.4 minutes (53% longer; ~35% of total runtime as added idle time)
- With 50 µs of jitter: 31.1 minutes (159% longer; ~61% of total runtime as added idle time)
- With 100 µs of jitter: unstable convergence and complete stalls.
The cost of a cloud service provider’s 512 A100 GPU cluster can easily exceed $20,000 per day—even at the low end. As Juniper’s test results show, this can easily include thousands of dollars in charges for GPU idle time caused by jitter.
Several factors contribute to jitter in AI environments: bursty, large-payload traffic from workloads that collides in shared networks; competition for resources in virtualized environments; and overhead from overlays like VXLAN—all of which introduce packet timing variations.
When AI workloads span multiple clouds and edge environments, jitter becomes even more pronounced. Cross-region hops in multi-cloud setups accumulate queuing delays. At the edge—where private 5G networks are common—mmWave signals are highly sensitive to obstacles, causing multipath fading that makes packet arrivals unpredictable. This is especially critical for real-time edge inference in applications like autonomous vehicles, smart factories, or AR/VR.
Jitter’s Knock-on Effect in Distributed AI Deployments
In distributed environments where AI workloads rely heavily on TCP for ordered, reliable packet delivery, jitter’s impact goes well beyond mere latency. It can lead to network throughput collapse. The reason is TCP’s congestion control algorithms (CCAs) that operate at the network transport layer (layer 4) consistently interpret jitter as a sign of congestion. To prevent data loss, TCP retransmits packets and throttles traffic even when the network isn’t saturated, and jitter stems from other factors.
Why Not Just Replace TCP?
In controlled data center environments, AI workloads can avoid TCP’s jitter response by using RDMA to copy data directly from one server’s memory to another’s, bypassing the OS network stack entirely. However, RDMA is generally impractical beyond the core data center, due to its specialized infrastructure requirements and reliance on lossless networking, which multicloud and wireless edge networks cannot guarantee.
Despite its flaws, TCP remains the backbone of distributed AI for good reason. TCP’s ordered, reliable delivery semantics make it ideal for AI workloads that depend on deterministic outcomes. Frameworks like PyTorch Distributed and Horovod are deeply tied to TCP, as are orchestration tools, monitoring platforms, and SLAs.
TCP is thoroughly embedded in the AI ecosystem—and ripping it out would come at a prohibitive cost. While protocols like QUIC offer potential, they lack TCP’s widespread adoption, particularly in AI frameworks. Replacing TCP would require rewriting distributed frameworks and re-architecting cloud and edge stacks, as well as retraining operations teams and risking compatibility issues throughout the entire AI pipeline. The only practical solution is to fix TCP’s flawed jitter response.
Traditional Remedies Fall Short
While TCP’s congestion control algorithms operate at the network transport layer, most network performance solutions don’t, or are only marginally effective if they do. Some make the problem worse:
- Bandwidth upgrades offer only a temporary fix. As traffic rises to the level of new capacity, the incidence of jitter-induced throughput collapse goes up in tandem. This leads to yet another round of costly and disruptive upgrades.
- QoS prioritizes some traffic flows, but introduces variability that creates jitter by suppressing others.
- SD-WAN reroutes traffic based on point-in-time conditions at network endpoints, but has no control beyond that.
- Jitter buffers reorder packets and realign their timing at the application layer, introducing their own delays unsuitable for time-critical AI.
- Advanced AI-driven networking can add packet timing variability through frequent traffic rerouting and configuration adjustments.
- TCP optimization adjusts congestion windows, uses selective ACKs, and modifies timeouts. Although TCP optimization does operate at the transport layer, performance improvements are only in the range of 10% to 15%, since it relies mainly on configuration adjustments and does nothing to stop TCP from misinterpreting jitter as a sign of congestion.
MIT Research recently flagged TCP’s CCAs as a growing challenge in today’s increasingly jitter-prone networks—yet offered no practical solution.2 Distributed AI needs a fundamentally different approach to TCP’s jitter response that integrates with existing infrastructure.
Overcoming AI’s Jitter Problem
To be effective, a solution must not only operate at the transport layer, it must also be able to determine in real-time whether jitter is due to network congestion, and prevent throughput collapse when it’s not. And it must do so transparently, without altering network stacks, applications, or network infrastructure.
Badu Networks’ WarpEngine does exactly that, and adds other network performance features to slash GPU idle time in distributed inference and training environments. Results speak volumes: 2-10x throughput gains for some of the world’s largest mobile operators, cloud providers, enterprises, and government agencies.3 WarpEngine supports TCP, UDP, GTP, and widely used encryption protocols such as IPsec. It’s deployable as hardware in core data center and edge locations, or as WarpVM in virtualized AWS, Azure, or KVM environments. WarpVM is also certified by multi-cloud platform and networking vendors such as Nutanix4 and others, demonstrating similar performance improvements to those cited above.
As organizations embrace distributed AI—ignoring jitter invites escalating costs in compute, energy, and opportunity. Addressing jitter head-on with WarpEngine unlocks AI’s potential, turning network headwinds into tailwinds for faster delivery with reliable results.
Interested in eliminating jitter and slashing GPU idle time in your AI workloads? Reach out to Badu Networks today to learn more or request a free trial/demo.
Notes
2. Starvation in End-to-End Congestion Control, August 2022: https://people.csail.mit.edu/venkatar/cc-starvation.pdf
3. Badu Networks Performance Case Studies: https://www.badunetworks.com/wp-content/uploads/2022/11/Performance-Case-Studies.pdf
4. Nutanix Technology Partners: https://www.nutanix.com/partners/technology-alliances/badu-networks