

Over 90% of large enterprises have moved from relying on a single cloud provider, to a hybrid multi-cloud architecture that combines on-premises infrastructure with multiple public clouds.1 They’ve done this largely as a defensive measure against outages like those mentioned in the title, caused by security and technology failures, as well as human error.2 Another driver has been the desire to control costs by leveraging the relative price and performance advantages each cloud vendor offers, which can vary by type of workload.
However, there are no standards for interoperability among public cloud platforms, and the vendors have little interest in creating any. Without the right tools in place, complete visibility and control across a hybrid multi-cloud implementation is virtually impossible. As a result, IT organizations have turned to hyper-converged infrastructure (HCI) platforms such as those offered by Nutanix, NetAPP, VMWare, Dell EMC, HPE, Microsoft Azure, Cisco, Scale Computing, Pivot3, and others.
HCI platforms minimize the complexity of hybrid multi-cloud deployments by turning the combination of on-premises and public cloud environments into a single logical cloud from both an operational and user perspective. There are two key components HCI platforms provide to achieve this. The first is a cloud-vendor agnostic layer of abstraction using either the HCI vendor’s own hypervisor that can be deployed in a variety of virtualized environments, or an integration layer that plugs into the hypervisor APIs of the cloud vendors they support. The second key component is a unified management plane that uses the HCI vendor’s abstraction layer to communicate with each node in a hybrid multi-cloud implementation. This makes it possible to manage and monitor the entire implementation across multiple cloud and on-premises environments through a single pane of glass, with automated provisioning, versioning, auto-scaling, HA/DR failover, security and other features.
To avoid performance bottlenecks, HCI platforms generally rely on a scale-out shared nothing architecture. They typically combine this with features that optimize each node’s CPU usage and storage access. However, there’s still an underlying cause of poor network throughput and slow application performance that all HCI platforms and cloud service providers lack a solution for – the massive amount of packet delay variation (PDV), more commonly referred to as jitter, inherent in virtualized environments.
Random VM scheduling conflicts, hypervisor packet delays, and hops between virtual and physical subnets combine with hosted web, streaming and IoT applications that send data in unpredictable bursts to generate massive amounts of jitter. RF-induced jitter from last-mile mobile and Wi-Fi networks on the client side compound it. TCP, the dominant network protocol used by AWS and other public clouds interprets jitter as a sign of congestion. It responds by slowing traffic to prevent data loss, even when the network isn’t saturated and plenty of bandwidth is available. Just modest amounts of jitter can cause throughput to collapse and applications to stall.
Although many think jitter buffers offer a solution, the opposite is true. Jitter buffers do nothing to prevent throughput collapse, and can even make it worse. The reason is TCP’s reaction to jitter occurs in the network transport layer, whereas jitter buffers are an application layer solution that realigns packet timing to adjust for jitter before packets are passed to an application. The random delays created by packet realignment not only ruin performance for real-time applications, they also become yet another source of jitter contributing to throughput collapse.
The only proven solution is WarpVMTM, the VM form factor of Badu Networks’ patented WarpEngineTM optimization technology used by some of the world’s largest mobile network operators, cloud service providers, government agencies and enterprises.3 With WarpEngine at its core, WarpVM can determine in real-time whether jitter is due to network congestion, and prevent throughput from collapsing and applications from stalling when it’s not. It builds on this with other performance enhancing features that benefit not only TCP, but also UDP and other traffic sharing a network regardless of protocol. Consequently, WarpVM can boost cloud network throughput and hosted application performance by up to 80% under normal operating conditions, and 2-10X or more in high traffic, high latency, jitter-prone environments.3 It achieves these results with existing infrastructure, at a fraction of the cost of budget busting VM and network upgrades that don’t address the root cause of poor performance. Instead, these upgrades end up increasing the incidence of jitter-induced throughput collapse over time, leading to yet another round of costly and disruptive upgrades.
Because it’s a VM-based transparent proxy, WarpVM can be deployed in minutes with any of the HCI platforms to work with their hypervisors, in the same way it’s deployed in standalone AWS, Azure, VMWare, or KVM environments. No changes to client or server applications or network stacks are needed. All that’s required are a few DNS changes at the client site to point to the WarpVM proxy, instead of the IP addresses of the VMs or containers hosting the target applications. This enables network traffic to be optimized before forwarding it to and from the target applications.
The image below shows how WarpVM is implemented with Nutanix, consistently recognized as a leader in the HCI space by Gartner and other industry analysts. Nutanix has certified WarpVM for use with its AHV hypervisor that enables the Nutanix Cloud Platform to span multiple cloud and on-premises environments.4
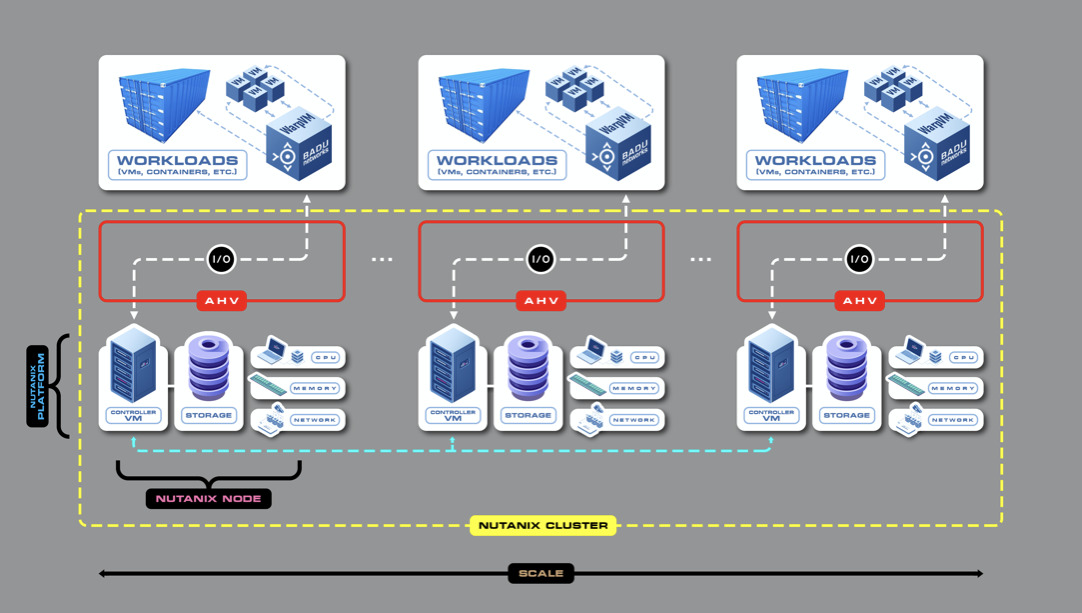
As shown above, one instance of WarpVM is installed with each instance of AHV in the Nutanix multi-cloud environment. This means WarpVM operates under the control of the same management, monitoring, security, backup and disaster recovery features as other applications running in VMs or containers on Nutanix cluster nodes distributed across public and private cloud environments. The deployment architecture is similar with other HCI platforms.
To learn more about WarpVM and request a free trial for your hybrid multi-cloud or single-cloud implementation, click the button below.
Notes
1.CIO.com Multi-Cloud Adoption and Consumption Trends – April 28, 2022
https://www.cio.com/article/309538/multi-cloud-adoption-and-consumption-trends.html
2. The 15 Biggest Cloud Outages of 2022 https://www.crn.com/news/cloud/the-15-biggest-cloud-outages-of-2022/13
3. Badu Networks Performance Case Studies: https://www.badunetworks.com/wp-content/uploads/2022/11/Performance-Case-Studies.pdf
4.Nutanix AHV Ready Certification https://www.nutanix.com/sg/partners/technology-alliances/badu-networks