
VM and network upgrades can improve poor cloud performance in the short-run, but lose effectiveness over time because they don’t address one of its major causes. As a result, successive rounds of increasingly expensive upgrades and budget-busting overprovisioning have become common across cloud deployments. Gartner and other industry analysts have cited overprovisioning as a significant source of the cost overruns expected to affect more than 60% of public cloud projects through 2024. 1
Overprovisioning isn’t only a problem for cloud customers. It also impacts cloud vendors. They obviously make more money when customers upgrade. However, the cloud vendor’s infrastructure and other support costs go up as well. In addition, cloud vendors operate in a highly competitive market. The competition has intensified in recent years as most IT organizations have now moved to a hybrid multi-cloud strategy to avoid vendor lock-in, and achieve greater cost control by leveraging the relative price and performance advantages each cloud vendor offers.
Why Cloud Network and VM Upgrades Ultimately Fail
The reason upgrades ultimately fail is that they don’t address the massive and constantly growing amount of packet delay variation (PDV), more commonly referred to as jitter, inherent in virtualized environments. Cloud environments are saturated with jitter from multiple sources. Random VM scheduling conflicts, hypervisor packet delays, and hops between virtual and physical subnets combine with hosted web, streaming and IoT applications that send data in unpredictable bursts, generating enormous amounts of jitter. RF interference and fading on last-mile mobile and Wi-Fi networks on the client side compound it. TCP, the dominant network protocol used by AWS and other public clouds consistently interprets jitter as a sign of congestion. It responds by slowing traffic to prevent data loss, even when the network isn’t saturated and plenty of bandwidth is available. Just modest amounts of jitter can cause throughput to collapse and applications to stall.
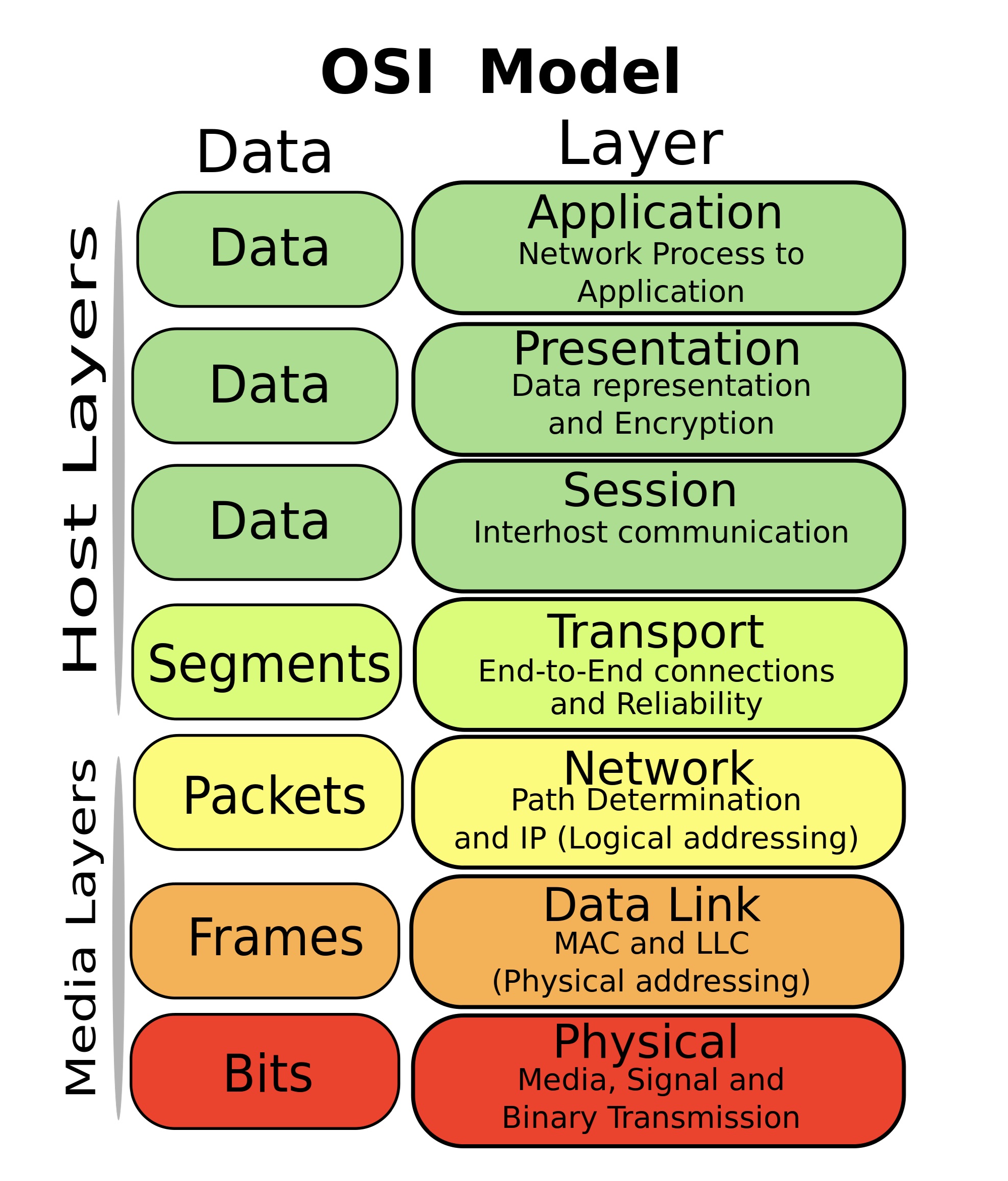
The Open Systems Interconnection (OSI) model provides a useful framework for understanding what’s required to overcome jitter-induced throughput collapse, and why upgrades and other performance solutions ultimately fall short. The OSI model, frequently used by network technology vendors to explain how their products work, divides network functionality into seven layers. For the purposes of this discussion, the physical (layer 1), transport (layer 4) and application (layer 7) are the most relevant. The physical layer includes the hardware supporting the network such as switches, cables and wireless access points. The transport layer provides higher level abstractions for coordinating data transfers between clients and servers. This includes where data is sent, the rate it’s sent at, and ensuring it’s transferred successfully. The application layer at the top of the stack represents the interface between user applications and the underlying network.
Bandwidth upgrades are primarily a physical layer solution. However, jitter-induced throughput collapse is triggered in the transport layer by TCP’s congestion control algorithms (CCAs), which lack the ability to determine whether jitter is caused by congestion or other factors, such as those cited above. Although upgrades do work for a time, traffic eventually increases to fill the additional capacity, and the incidence of jitter-induced throughput collapse goes up in tandem.
VM upgrades often happen in conjunction with cloud network upgrades to support higher bandwidth connections. For larger network upgrades, additional VMs may also be deployed. For example, consider a cloud customer that is currently paying for a 10G connection. They want to upgrade for a 3X improvement in throughput. Most network administrators assume only 30% utilization for each connection to allow enough headroom for peak traffic, in part because of the bandwidth wasted by TCP’s reaction to jitter. To achieve a 3X boost, they would typically pay for two more 10G connections, and two additional VMs to support each connection. They would then balance traffic across the three connections and their associated VMs.
It’s also not uncommon for network driven performance problems to be attributed to VM sizing issues. This often leads to unnecessary VM upgrades taking place independent of network upgrades.
Other Solutions Fall Short
When network administrators do identify jitter as a factor in lagging performance, they often turn to jitter buffers to resolve it. However, jitter buffers do nothing to prevent throughput collapse, and can even make it worse. TCP’s reaction to jitter occurs in the transport layer, whereas jitter buffers are an application layer solution that realigns packet timing to adjust for jitter before packets are passed to an application. The random delays created by packet realignment can ruin performance for real-time applications, and become yet another source of jitter contributing to throughput collapse.
SD-WAN, a more recent addition to the list of network performance tools, makes it possible to offload branch office internet and cloud-bound traffic from leased line and MPLS links to less expensive broadband. The architectural and cost advantages are obvious. However, there’s also a widespread assumption that SD-WAN can optimize performance merely by choosing the best available path among broadband, LTE, 5G, MPLS, Wi-Fi or any other available link. The problem is SD-WAN makes decisions based on measurements at the edge, but has no control beyond it. What if all paths are bad?
In combination with SD-WAN, a variety of techniques that fall under the heading of network QoS (quality of service) are often deployed. These include:
- Packet prioritization to insure that higher priority application traffic is given preference over other application traffic.
- Traffic shaping that controls the rate at which data is sent over the network, smoothing out traffic bursts in an attempt to avoid congestion.
- Resource reservation that reserves bandwidth for specific applications or users, to maintain a minimum service level.
While these approaches can offer some benefit, they don’t address jitter-induced throughput collapse, and to some extent they’re impacted by it.
To eliminate jitter-induced throughput collapse, the focus must be on layer four, the transport layer. This is where TCP’s congestion control algorithms (CCAs) become a bottleneck by reducing throughput in reaction to jitter, even when the network isn’t saturated and ample bandwidth is available. Most TCP optimization solutions that do focus on the transport layer try to address this bottleneck by managing the size of TCP’s congestion window to let more traffic through a connection, using selective ACKs that notify the sender which packets need to be retransmitted, adjusting idle timeouts and tweaking a few other parameters. While these techniques can offer some modest improvement, generally in the range of ten to fifteen percent, they don’t eliminate jitter-induced throughput collapse, the resulting waste of bandwidth, or its impact on UDP and other traffic.
Jitter-induced throughput collapse can only be resolved by modifying or replacing TCP’s congestion control algorithms to remove the bottleneck they create, regardless of the network or application environment. However, to be acceptable and scale in a production environment, a viable solution can’t require any changes to the TCP stack itself, or any client or server applications. It must also co-exist with ADCs, SD-WANs, VPNs and other network infrastructure already in place.
There’s Only One Proven and Cost-Effective Solution
Only Badu Networks’ patented WarpEngineTM optimization technology, with its single-ended proxy architecture meets the key requirements outlined above for eliminating jitter-induced throughput collapse. WarpEngine determines in real-time whether jitter is due to network congestion, and prevents throughput from collapsing and applications from stalling when it’s not. It builds on this with other performance enhancing features that benefit not only TCP, but also UDP and other traffic sharing a network as well, to deliver massive performance gains for some of the world’s largest mobile network operators, cloud service providers, government agencies and businesses of all sizes. 2
WarpVMTM , the VM form factor of WarpEngine, is designed specifically for cloud environments. With WarpEngine at its core, WarpVM can boost cloud network throughput and hosted application performance by up to 80% under normal operating conditions, and 2-10X or more in high traffic, high latency, jitter-prone environments.WarpVM achieves these results with existing infrastructure, at a fraction of the cost of budget-busting VM and network upgrades.
Because it’s a VM-based transparent proxy, WarpVM can be deployed in minutes in AWS, Azure, VMWare, or KVM environments. No modifications to client or server applications or network stacks are required. All that’s needed are a few DNS changes at the client site to point to the WarpVM proxy instead of the IP addresses of the VMs or containers hosting the target applications. This enables network traffic to be optimized before forwarding it to and from the target applications. WarpVM has also been certified by NutanixTM for use with their multicloud platform, achieving similar performance results to those cited above. 3
Comparing the Cost of WarpVM to the Cost of Cloud Network and VM Upgrades
To understand how the cost of implementing WarpVM compares to the cost of VM and network upgrades to achieve the same result, I’ll refer to the earlier example of the cloud customer with a 10G network connection that wants to improve performance by 3X. This is approximately the average boost in throughput seen with WarpVM. I’ll also use current AWS pricing for comparison purposes. As of this writing, AWS charges $1642.50 per month for 10G port capacity.4 This does not include AWS server (VM) costs. To achieve this without WarpVM, the AWS customer would pay for two additional 10G ports, and two additional
VMs. They would then balance load across them, typically at 30% utilization each, to allow headroom for peak traffic. The additional cost would be $3285/month (1642.50 X 2), excluding charges for additional VMs that meet specs for CPU, memory, storage, etc. While AWS makes more money in an upgrade scenario, their internal infrastructure costs to support the upgrade also go up, as is the case with all cloud vendors.
In comparison, to improve throughput by 3X using WarpVM in this scenario, the customer would only pay $883 per month at list price, for a savings of $2402 per month. This is 73% less than the cost of AWS connection costs alone. In reality the savings are much greater, because no additional AWS servers are required. WarpVM makes them unnecessary, since there’s no need to limit each connection’s utilization to 30%, and balance traffic across multiple VMs. WarpVM also makes it less likely that another round of upgrades would be required, since the underlying problem of jitter-induced throughput collapse has been resolved, and the bandwidth that was previously wasted has been recaptured.
Cloud customers using WarpVM will enjoy massive savings and a better overall quality of experience (QoE) than VM and network upgrades can deliver. In addition, cloud vendors offering WarpVM as an upgrade option would no longer have to bear the cost of provisioning additional infrastructure in most cases. They could choose to pass some or all the savings along to their customers, and gain immediate competitive advantages in terms of price, performance and customer QoE.
To learn more about WarpVM and request a free trial click the button below.
Notes
1. Gartner: 6 Ways Cloud Migration Projects Go Off the Rails, July 7, 2021: https://www.gartner.com/smarterwithgartner/6-ways-cloud-migration-costs-go-off-the-rails
2. Badu Networks Performance Case Studies: https://www.badunetworks.com/wp-content/uploads/2022/11/Performance-Case-Studies.pdf
3. https://www.nutanix.com/partners/technology-alliances/badu-networks